Help us build THE WORLD‘S LARGEST, OPEN, BILLION-SCALE Image-Text-Dataset – Perfect for training DALL-E, CLIP & other multimodal models
Fundraising campaign by
Christoph Schuhmann

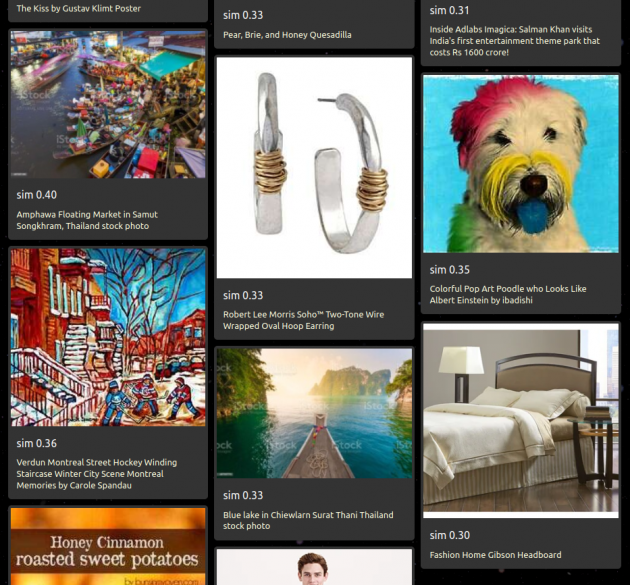


-
US$75.00Donated So Far
Campaign Story
We already released LAION-400M, the world’s largest openly available image-text-pair data-set with 400 million samples.( https://laion.ai/laion-400-open-dataset/ )
- Now we need your support to build a DATASET WITH BILLIONS of IMAGE-TEXT-PAIRS, each of high quality, with text that fits really well to the image.
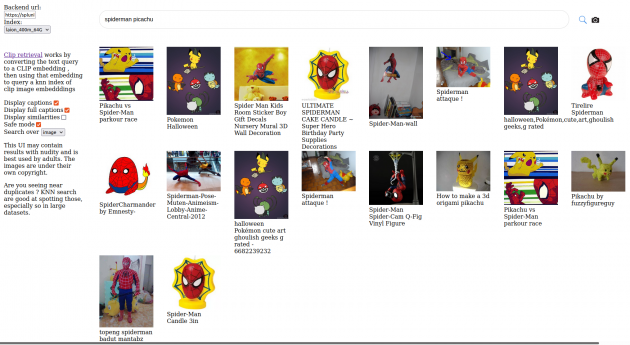
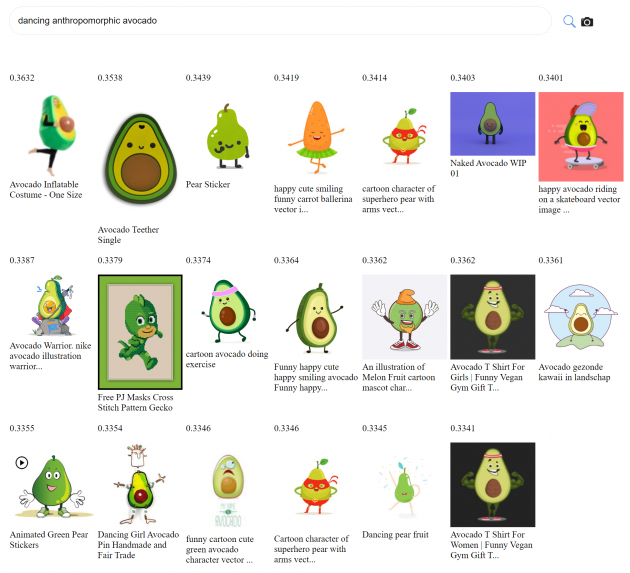
Together with the data-set we will also release a K-nearest neighbor index, that allows you to explore the data-set easily by performing image and text similarities searches.Is this enables you to easily domain specific data sets by filtering out sub sets.
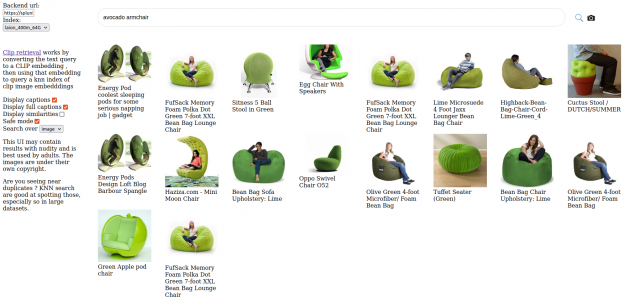
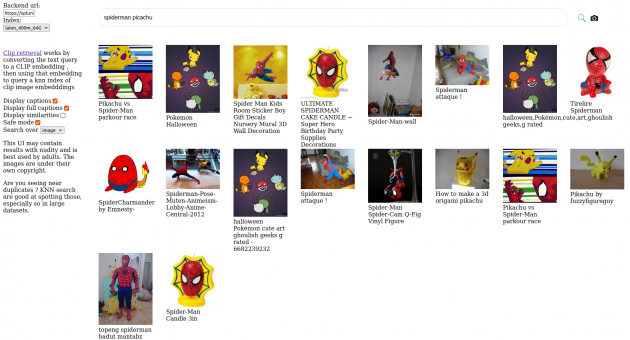
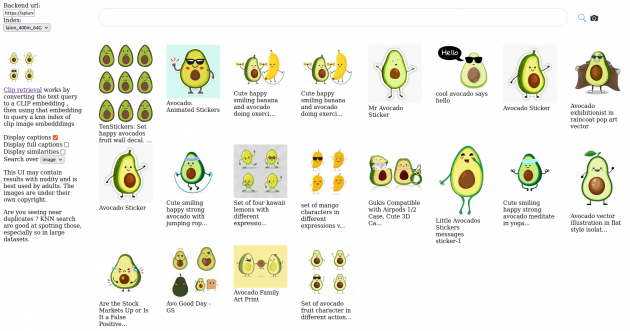
Here can you find a graphical user interface for the index be released with 400 million data-set:
The project started in April with one PC and evolved on the DALL-E Discord server, Where more and more people contributed by improving the code and donating time on their computers.
As we began to realize in July that we will reach the hundreds of millions within the next months, we decided to aim for several billions of samples and to create a nonprofit organization as a structure that allows us to receive funding for this and hopefully many more exciting projects to come!
Here can you find our homepage:
- We all work in our free time, completely for free. Many of us spent hundreds, some of us even thousands of dollars of our private money to get us this far and to release the LAION 400M data-set.
Now we need your support to get to sufficient funding to extend or a data-set into the billions!
For every 5.000$ we get we will be able to extend our data-set by at least 1 billion samples, conservatively estimated, … likely by more!
This will enable researchers & organizations from all over the world to ...
- to train gigantic models like DALL-E and CLIP ... BUT MUCH BIGGER (!) ...
- to easily build LARGE DOMAIN-SPECIFIC DATASETS with our KNN index and
- to easily analyze captions & images of SIGNIFICANT PARTS OF THE INTERNET.
SUPPORT US NOW BY
- Spreading the word by talking with your friends & colleagues about LAION 400M and our goal to extend it into the 2-digit billions.
- Sharing the links to this campaign & to LAION 400M on Twitter, Discord, Youtube, Facebook, Instagram and other social media platforms you're using.
- Using LAION 400M in your research or company to train EPIC MODELS with it and to write AWESOME PAPERS.
- Donating money to this campaign.

( If you have any questions, don't hesitate to join the DALL-E Discord server & chat with us in the CRAWLING@HOME section )
Organizer
- Christoph Schuhmann
Donors
- Jimmie
- Donated on Sep 20, 2021
- funny ai
- Donated on Sep 16, 2021
- Anonymous
- Donated on Sep 15, 2021
No updates for this campaign just yet
Donors & Comments
- Jimmie
- Donated on Sep 20, 2021
- funny ai
- Donated on Sep 16, 2021
- Anonymous
- Donated on Sep 15, 2021
